Hi guys,
I’m about to create my first web service, and I need validation on how data is managed between the UI that is requesting a particular JSON format, and a relational database which organise the data differently.
To illustrate a little bit, I’m gonna take a simple example of an overly simplified database for an Hotel:
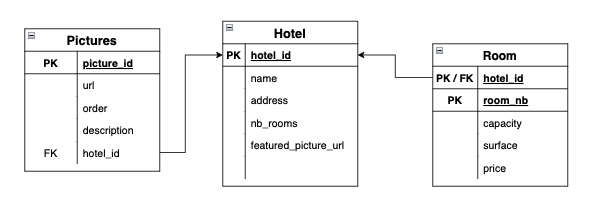
An hotel has some fields, it has rooms and pictures, nothing fancy here.
To unmarshall the SQL response from the Hotel DB, I would create these simple structs…
type Hotel struct {
HotelId string `json:"hotel_id"`
Name string `json:"name"`
Address string `json:"address"`
NbRooms int32 `json:"nb_rooms"`
Pictures []Picture `json:"pictures"`
Rooms []Room `json:"hotel_rooms"`
}
type Picture struct {
Url string `json:"url"`
Order string `json:"order"`
Description string `json:"description"`
}
type Room struct {
RoomNb string `json:"room_nb"`
Capacity string `json:"name"`
Surface string `json:"surface"`
Price float32 `json:"price"`
}
… On the other hand, when the UI is performing requests to populate its views, it just wants to only retrieve the necessary data, and in a format that may not always match the structs above.
For example, we can imagine that the UI would want to get the available Hotels (depending on dates, prices etc…) but only some specific information like the name, the address, the number of rooms that’s it. For some reason, the UI doesn’t want to get images of any kind or any more information about an Hotel.
{
"hotel_list":[
{
"hotel_id": "0001",
"name": "The Nice Hotel",
"address": "...",
"nb_rooms": 4,
},
{
"hotel_id": "0001",
"name": "The Nice Hotel",
"address": "..." "nb_rooms": 4,
}
]
In order to satisfy the UI need, the Hotel API would need other type of structs that would match the UI data requirement:
var hotelList = []HotelListItem{}
type HotelListItem struct {
HotelId string `json:"hotel_id"`
Name string `json:"name"`
Address string `json:"address"`
NbRooms int32 `json:"nb_rooms"`
}
This means that the model would be in charge of transforming the struct result of the SELECT request sent to the database, into a struct that would fit the response the UI is waiting for. In other words, the “domain” part of the Book service would not only contain the CRUD methods, but also transformation methods to do this job.
What do you think about these assumptions?
We can imagine that the number of “transform” functions may grow and take a lot of place because of the UI is building hundreds of different views which would make the DTO bigger and bigger … Even if we could imagine several view using the same JSON response format, is there any other strategy to be implemented in this kind of situation?
Here’s a link to a diagram to illustrate a little bit:
If you can advise lectures on the subject, I’ll take them.
Many thanks for your help 