Good day all,
My first post here.
Please can someone assist me with this. I have started using Colly. I have been successful thus far with getting information that I need from various websites.
However I now have hit a dead end. Lets take this url as an example:
I have managed to pull the item description with the below code perfectly :

func ScrapeData (){
// Instantiate default collector
c := colly.NewCollector()
c.OnHTML("body" , func(e *colly.HTMLElement) {
// Extract the Class Name from the HTML Body element
fmt.Printf("** Program is running ** \n")
// Assign the scraped data to variables
name:= e.ChildText(".prod-name")
price:= e.Attr(".price prod--price")
// print the data obtained
fmt.Println("Description of item : "+ name)
fmt.Println("The price of the item is : "+ price)
})
// Vist the url that the data will be scraped from
c.Visit("https://www.woolworths.co.za/prod/Food/Food-Cupboard/Coffee-Tea-Hot-Drinks/Coffee/Instant-Coffee/Espresso-Instant-Coffee-100-g/_/A-6009175211321")
}
The Html looks like below
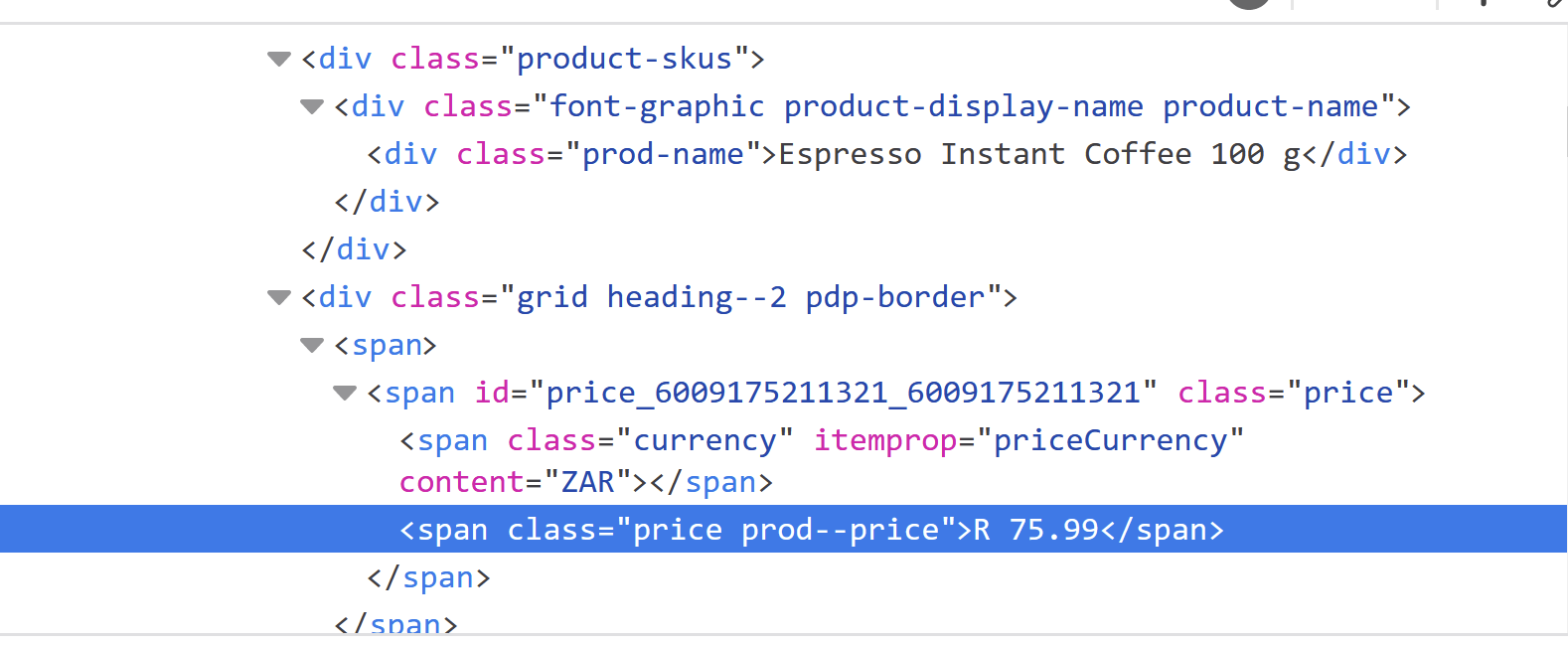
The .prod-name found on the webpage come through perfectly.
The price prod–price does not come through.
I have a number of options but just could not get this right so I decided to post it here as there might be someone more experienced that could shed some light on the issue.
Thanks so much